
$24,680 - GPU 한 대가 만드는 이익
NVIDIA H100 SXM GPU 한 대의 제조원가는 약 $3,320이다. NVIDIA가 하이퍼스케일러에게 판매하는 가격은 약 $28,000. 차이는 $24,680, 총이익률 88%.
하드웨어 업계에서는 보기 드문 수준이다. Apple iPhone의 총이익률이 약 43%, TSMC의 파운드리 서비스가 약 55%, 삼성 반도체가 약 35%인 것과 비교하면, NVIDIA의 88%는 소프트웨어 기업에 가까운 마진 구조다.
이런 마진이 어떻게 가능한지, 그리고 이 구조가 AI 생태계 전체에 어떤 영향을 주는지 살펴본다. 업계에서는 이를 “NVIDIA Tax” - AI를 운영하려면 직·간접적으로 NVIDIA에 지불하게 되는 프리미엄 - 라고 부르기도 한다.
NVIDIA의 지배력: 숫자로 보는 독점
시장 점유율 추이
NVIDIA의 AI 가속기 매출 기준 시장점유율은 2024년에 87%로 피크를 기록했다. 이후 AMD의 MI300 시리즈와 커스텀 ASIC 확대로 소폭 하락하고 있으나, 여전히 압도적이다.
| 연도 | NVIDIA | AMD | Intel + 기타 | 커스텀 ASIC |
|---|---|---|---|---|
| 2023 | ~92% | ~3% | ~3% | ~2% |
| 2024 | ~87% | ~5% | ~2% | ~6% |
| 2025E | ~80% | ~8% | ~2% | ~10% |
| 2026E | ~75% | ~10% | ~2% | ~13% |
주목할 점은 NVIDIA의 점유율이 하락하더라도, 시장 자체가 빠르게 성장하고 있어 절대 매출은 계속 증가한다는 것이다. NVIDIA의 데이터센터 매출은 FY2025(2024.2-2025.1)에 $115.2B으로 전년 대비 142% 성장했다.
NVIDIA의 수직 통합 전략
NVIDIA의 독점은 단순히 “좋은 GPU를 만든다”가 아니다. CUDA 생태계라는 소프트웨어 해자(moat)가 핵심이다.
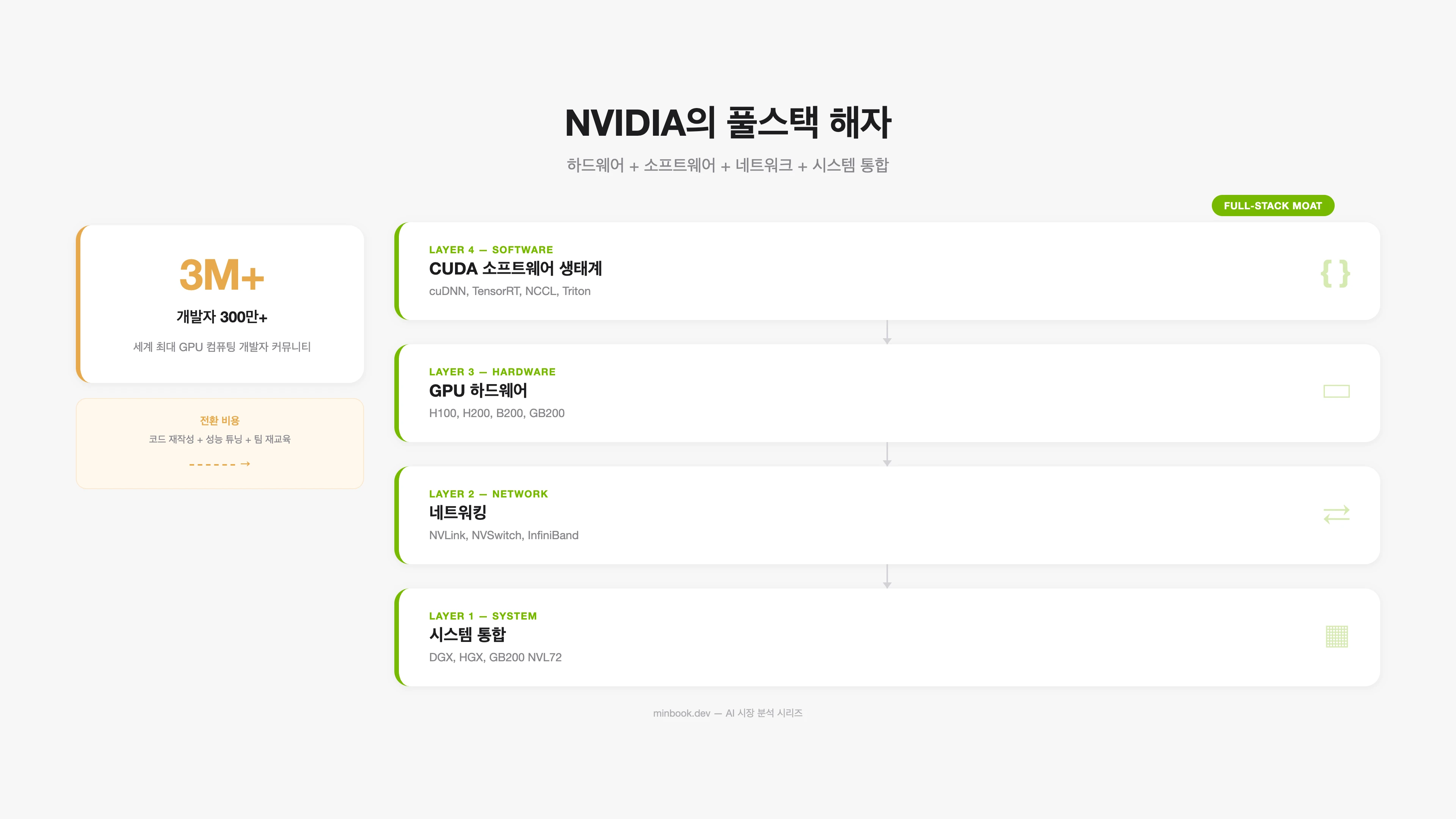
CUDA 락인(Lock-in)의 실체:
-
개발자 생태계. 전 세계 AI/ML 개발자 중 CUDA를 사용하는 비율은 90% 이상으로 추정된다. PyTorch, TensorFlow, JAX 등 주요 프레임워크가 모두 CUDA를 기본 백엔드로 사용한다.
-
최적화 라이브러리. cuDNN(딥러닝), TensorRT(추론 최적화), NCCL(멀티 GPU 통신) 등 수백 개의 최적화 라이브러리가 NVIDIA GPU에 맞춰져 있다. AMD의 ROCm이나 Intel의 oneAPI가 존재하지만, 성능과 안정성에서 아직 격차가 있다.
-
전환 비용. CUDA로 작성된 AI 워크로드를 다른 플랫폼으로 옮기려면 코드 재작성, 성능 튜닝, 테스팅이 필요하다. 대규모 모델 학습의 경우 이 전환에 수개월이 소요될 수 있다.
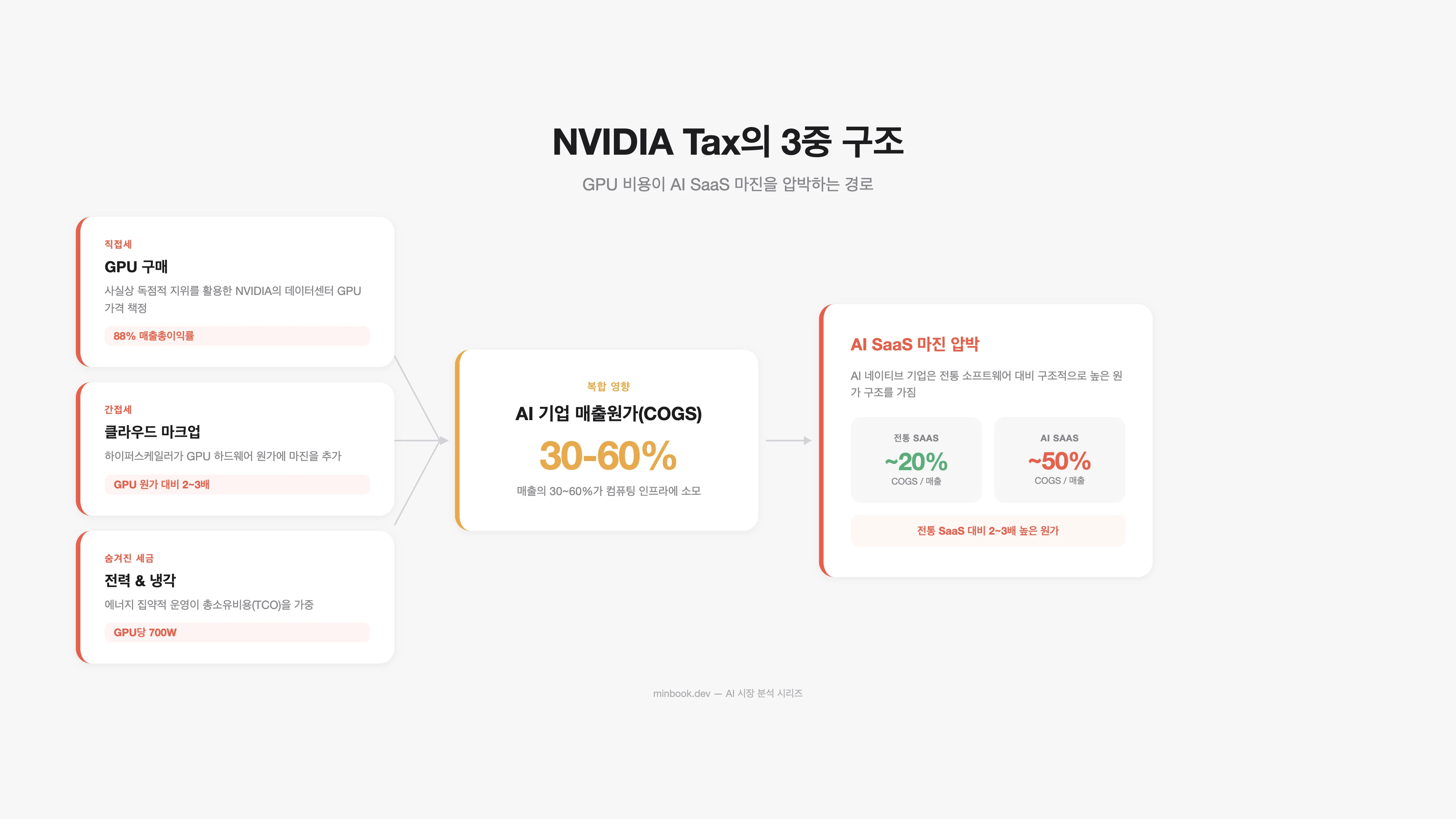
”NVIDIA Tax”의 구조
“NVIDIA Tax”는 AI를 운영하는 모든 기업이 직·간접적으로 NVIDIA에 지불하는 프리미엄이다. 이 세금은 여러 경로로 부과된다.
직접세: GPU 구매
하이퍼스케일러가 NVIDIA에 직접 지불하는 비용이다. 2026년 Top 5 하이퍼스케일러의 CapEx 전망이 $602B-$690B인데, 이 중 상당 부분이 NVIDIA GPU 구매에 사용된다.
| GPU 모델 | 출시 | 가격 (대당) | 주요 특성 |
|---|---|---|---|
| H100 SXM | 2023 | ~$28,000 | 80GB HBM3, 학습 표준 |
| H200 | 2024 | ~$35,000 | 141GB HBM3e, 추론 최적화 |
| B200 | 2025 | ~$40,000 | 차세대 Blackwell |
| GB200 NVL72 | 2025 | ~$2.3M (72 GPU 랙) | 초대규모 학습/추론 |
간접세: 클라우드 GPU 마크업
AWS, Azure, GCP는 NVIDIA GPU를 구매한 뒤 클라우드 서비스로 재판매한다. 여기에 2-3배의 마크업이 추가된다.
| 항목 | 비용 |
|---|---|
| NVIDIA가 하이퍼스케일러에게 파는 H100 가격 | ~$28,000 |
| 하이퍼스케일러의 H100 클라우드 인스턴스 3년 누적 매출 | ~$80,000-$120,000 |
| AI 스타트업이 실제로 지불하는 연간 GPU 비용 | 매출의 30-60% |
결과적으로, AI SaaS 기업의 매출 원가(COGS) 중 GPU/추론 비용이 차지하는 비중이 **30-60%**에 달한다. 전통 SaaS의 COGS가 15-25%인 것과 비교하면 2-3배 높다. 이것이 AI SaaS의 마진을 구조적으로 압박하는 원인이다.
숨겨진 세금: 전력과 냉각
NVIDIA GPU의 전력 소비도 “세금”의 일부다. H100 한 대의 TDP(Thermal Design Power)는 700W. GB200 NVL72 랙은 120kW. 데이터센터 전체 전력 비용 중 GPU가 차지하는 비중이 급격히 늘고 있다.
독점이 깨질 수 있는 3가지 시나리오
NVIDIA의 현재 지배적 위치가 지속될 것인지에 대해서는 여러 관점이 있다. 구조적 변화가 일어날 수 있는 세 가지 방향을 살펴본다.
시나리오 1: 커스텀 ASIC의 부상
Google(TPU), Amazon(Trainium/Inferentia), Microsoft(Maia), Meta(MTIA)가 모두 자체 AI 칩을 개발하고 있다. 이 칩들은 특정 워크로드(주로 추론)에 최적화되어 있어, NVIDIA GPU 대비 비용 효율이 2-5배 높을 수 있다.
| 칩 | 개발사 | 주요 용도 | 대 NVIDIA 장점 |
|---|---|---|---|
| TPU v6 (Trillium) | Gemini 학습/추론 | TCO 50% 절감 주장 | |
| Trainium2 | Amazon | Bedrock 추론 | 비용 30-50% 절감 |
| Maia 100 | Microsoft | Azure AI 추론 | 자체 인프라 최적화 |
| MTIA v2 | Meta | Llama 추론/랭킹 | 추론 특화 효율 |
한계: 커스텀 ASIC은 학습(Training)보다는 추론(Inference) 워크로드에 집중되어 있다. 범용 학습 워크로드에서는 NVIDIA GPU의 유연성과 CUDA 생태계를 대체하기 어렵다. 또한, 각 하이퍼스케일러의 커스텀 칩은 자사 클라우드에서만 사용 가능하므로 시장 전체의 경쟁 구도를 바꾸기보다는 자사 CapEx 절감에 가깝다.
시나리오 2: AMD의 추격
AMD의 MI300X/MI325X는 HBM 용량에서 NVIDIA를 앞서며, ROCm 소프트웨어 스택도 개선되고 있다. 2025년 AMD의 AI 가속기 매출은 ~$8B으로 추정되며, 시장점유율은 ~8%로 성장 중이다.
핵심 변수: ROCm의 성숙도. CUDA 대비 ROCm은 여전히 라이브러리 호환성, 디버깅 도구, 커뮤니티 지원에서 격차가 있다. 하지만 PyTorch의 ROCm 지원이 안정화되면서 전환 비용이 점진적으로 낮아지고 있다.
시나리오 3: 추론 효율화로 GPU 수요 감소
가장 흥미로운 시나리오다. 모델 경량화, 양자화(Quantization), 혼합 정밀도(Mixed Precision), MoE(Mixture of Experts) 아키텍처 등의 기술 발전으로 같은 작업에 필요한 GPU 수가 줄어드는 상황이다.
DeepSeek-V3는 MoE 아키텍처를 통해 학습 비용을 기존 대비 90% 이상 절감했다고 주장한다. 이런 효율화가 일반화되면, NVIDIA의 절대 매출이 아닌 성장률에 영향을 줄 수 있다.
“추론 비용이 24개월에 280배 하락했다는 것은, 같은 작업을 수행하는 데 필요한 GPU가 280분의 1로 줄었다는 뜻이기도 하다. 물론 사용량이 훨씬 더 빠르게 늘었기 때문에 절대 수요는 증가했지만, 이 효율화 추세가 계속되면 수요 증가율을 따라잡는 시점이 올 수 있다.”
AI 기업을 위한 시사점
비용 구조 점검
AI 제품/서비스를 운영하는 기업이라면, GPU/추론 비용이 매출에서 차지하는 비율을 명확히 파악해야 한다.
| GPU 비용 비중 | 상태 | 대응 |
|---|---|---|
| 매출의 60% 이상 | 위험 | 모델 경량화, 캐싱, 배치 최적화 우선 |
| 매출의 30-60% | 주의 | 멀티 클라우드, 스팟 인스턴스 활용 |
| 매출의 30% 미만 | 양호 | 마진 여유분을 제품 차별화에 투자 |
멀티 벤더 전략
NVIDIA 단일 의존도를 줄이는 것이 장기적 리스크 관리다. 구체적으로:
- 추론과 학습을 분리. 학습은 NVIDIA GPU, 추론은 커스텀 ASIC이나 AMD로 분산
- 추상화 레이어 도입. vLLM, TensorRT-LLM 등 추론 최적화 프레임워크를 활용해 하드웨어 전환 비용을 낮춤
- 클라우드 GPU 단가 비교. 같은 GPU라도 AWS, Azure, GCP, CoreWeave, Lambda Labs 간 가격 차이가 20-40%
Sources
- H100 원가/마진 분석 - Jarvislabs, Cyfuture Cloud
- NVIDIA 시장점유율 - Silicon Analysts, Carbon Credits (2025.01)
- NVIDIA FY2025 실적 - NVIDIA 10-K Filing (SEC), Data Center Revenue $115.2B
- CUDA 생태계 - NVIDIA Developer Program, CUDA-X Libraries (3M+ devs)
- Hyperscaler CapEx - IEEE Communications Society (2025.12), CNBC (2026.02), Futurum Group (2026.02)
- Google TPU v6 - Google Cloud Blog “Introducing Trillium”, Trillium GA
- Amazon Trainium2 - AWS re:Invent 2024 Recap, Amazon Q4 2025 Earnings Transcript
- AMD AI 가속기 - AMD Q4 2025 Earnings, Motley Fool (2026.01)
- LLM 추론 비용 하락 - Stanford AI Index 2025, a16z “LLMflation”
- DeepSeek-V3 효율화 - DeepSeek Technical Report (arXiv), Epoch AI Analysis
관련 글

AI 시장 3영역 해부 - $660B 시장의 실제 구성
AI 시장을 인프라($500B+), 플랫폼($18B+), 애플리케이션($80B+) 3개 영역으로 나눠 분석한 시리즈 첫 편

AI 가치는 어디에 쌓이나: Benedict Evans와 Jensen Huang의 두 시각
Evans 세션과 Jensen 키노트를 정리하고, 둘이 모델 커머디티화에 공감하면서 가치의 방향에서 갈리는 지점을 본다

AI eats the world 2026 - Benedict Evans 79장 deck 정리
Evans 2026 deck 79장 정리. 자본·도입·변화 3챕터 + 인프라 폭발이 가치 포착으로 안 이어진다는 한 가지 질문