
한국 금융 광고는 캠페인 한 건이 나가기까지 보통 한 달 이상이 걸린다고 알려져 있고, 그중 적지 않은 비중이 리서치와 심의에 들어간다고 한다. 금융소비자보호법(금소법), 표시광고법, 여신금융협회·생명보험협회·금융투자협회 같은 업권별 자율심의 가이드라인을 모두 거쳐야 하고, 그사이 경쟁사 캠페인·네이버 트렌드·자사 상품 약관·과거 승인 카피를 교차 확인하는 일이 반복되곤 한다(필자가 해당 산업에서 일해 본 적은 없으니, 이 부분은 업계 종사자분들의 보정이 필요한 영역이다).
이런 구조에서 멀티 에이전트(Multi-Agent)는 매력적인 도구처럼 보이지만, 한 번에 풀스택을 짜려고 들면 같은 자리에서 막히는 사례가 자주 보인다 - 누가 무엇을 결정할 권한을 갖는가가 흐려지기 때문이다.
이 글에서는 그 함정을 피하는 한 가지 방법으로 단계적 도입(Phased Approach) 의 시각을 풀어 본다. Phase 1은 도구, Phase 2는 동료, Phase 3은 팀으로 권한이 점진적으로 옮겨가는 그림이며, 각 단계마다 컴포넌트 도식·핵심 패턴·한계 시나리오를 짝지어 본다. 어디까지나 하나의 예시 시나리오이고, 실제 조직마다 출발점·범위·속도는 달라질 수 있다.
광고 기획자 작업 흐름 - 한 가지 예시
자동화 범위를 가늠하기 전에 사람이 어떤 단계를 거치는지 한 번 펼쳐 보면 설계가 훨씬 쉬워진다. 회사·업권·상품에 따라 단계 구성과 순서는 달라지겠지만, 한국 금융사 마케팅 부서에서 캠페인 1건이 흘러가는 흐름을 한 가지 예시로 정리해 보면 대략 다음과 같이 그릴 수 있다.
| Phase | 단계 | 핵심 인풋 | 핵심 아웃풋 |
|---|---|---|---|
| 브리핑 | 캠페인 목적 정의 | 사업부 요청, 분기 KPI | 목표·예산·일정 |
| 브리핑 | 상품 스펙 파악 | 약관, 비교공시 | 금리·한도·수수료·위험요소 |
| 리서치 | 규제 스캔 | 금소법, 협회 가이드, 금감원 행정지도 | 필수 표시·금지 표현 체크리스트 |
| 리서치 | 경쟁사 벤치마크 | 홈페이지·유튜브·SNS·검색광고 | 메시지·톤·채널 매트릭스 |
| 리서치 | 트렌드 분석 | 네이버 DataLab, 커뮤니티 | 상승 키워드·이슈 |
| 리서치 | VoC·페르소나 | CRM, 콜센터, 리뷰 | 페인포인트·니즈 |
| 기획 | 컨셉 도출 | 위 모든 인풋 | 캠페인 컨셉 2~3안 |
| 기획 | 카피·CTA 작성 | 컨셉, USP, 페르소나 | 헤드라인·서브카피·의무표시 |
| 기획 | 채널 믹스 | 예산, 매체 적합도 | 채널별 KPI·예산 |
| 심의 | 셀프 컴플라이언스 | 카피 + 규제 체크리스트 | 위반 위험도 리포트 |
| 심의 | 법무·컴플라이언스 검토 | 1차 통과본 | 수정 코멘트 |
| 심의 | 협회 사전심의 | 최종 소재 | 심의필 또는 수정 요구 |
| 집행 | 송출·모니터링 | 라이브 데이터 | 실시간 성과·민원 알림 |
| 집행 | 사후 학습 | 성과 데이터 | 다음 캠페인 인풋 |
이런 흐름을 펼쳐 놓고 보면, 자동화 적합도가 비교적 높은 구간은 리서치(규제 스캔, 경쟁사 벤치마크, 트렌드)와 셀프 컴플라이언스 쪽이고, 사람의 결정이 남는 게이트는 캠페인 목적 정의, 컨셉 선택, 법무 sign-off 정도가 자주 거론된다.
단계적 접근(Phased Approach)이라는 시각
이 흐름 전체를 한 번에 멀티 에이전트로 옮기려는 시도는 보통 두 가지 지점에서 막히곤 한다. 첫째, 사람과 AI가 어디서 권한을 주고받는지가 흐려진다. 둘째, 컴플라이언스가 사후 검증이 아니라 흐름 안에 들어가야 한다는 제약을 잘 다루지 못한다. 이 두 가지를 한꺼번에 풀려 들수록 시스템은 무거워지고 실제 운영에서는 자주 정지한다.
대안은 자동화 범위와 사람의 결정권을 단계별로 나누는 접근이다. 리서치·정보 수집처럼 산출물 책임이 가벼운 영역부터 자동화하고, AI가 산출물을 만들기 시작하는 시점부터는 명시적 HITL 게이트를 깔아 둔 다음, AI끼리 결과를 주고받는 단계는 가장 마지막에 검토하는 식이다.
한 가지 예시 - 3단계 시나리오
아래 표는 그 단계적 접근을 한 가지 예시로 정리해 본 것이다. 실제 조직에서는 단계 구분도 다를 수 있고, 한 단계에 머무르는 게 더 합리적인 경우도 적지 않다.
| Phase | 자동화 범위 | 사람의 역할 | 스택 한 줄 |
|---|---|---|---|
| 1 | 리서치 + 셀프 컴플라이언스 | 기획·작성·결정 대부분 | RAG Agent + Tool 몇 개 |
| 2 | 리서치 + 기획 초안 + 카피 + 채널 믹스 | 게이트 몇 곳에서 결정·승인 | 협업 멀티 에이전트 + HITL |
| 3 | 거의 전 구간 + 사후 학습 + 이벤트 자동 대응 | 거버넌스·예외 처리 중심 | 매크로 오케스트레이터 + 메모리 레이어 + Observability |
세 단계 사이의 질적 변화는 두 임계점으로 정리해 볼 수 있다. Phase 1과 2 사이의 임계점은 “AI가 산출물을 만들기 시작하는 것” - 이때부터 책임 소재가 모호해져 HITL(Human-in-the-Loop) 게이트 설계가 곧 거버넌스 설계로 이어진다. Phase 2와 3 사이의 임계점은 “AI끼리 결과를 주고받는 것” - Critic이 Copywriter의 결과를 reject할 권한을 갖게 되면서 에이전트 간 권한 위계를 새로 잡을 필요가 생긴다.
Phase 1 - Research Co-pilot
사람이 쓴다, AI는 모은다.
이 단계는 비교적 가볍게 시작해 볼 수 있다. 한 가지 예시로 풀자면 RAG 한 덩어리 + Tool 몇 개 + ReAct 루프 정도의 조합이 있고, 단순 워크플로우 자동화나 노트북 기반 LLM 보조 같은 다른 출발점도 충분히 가능하다. 어느 쪽이든 리서치·셀프 컴플라이언스 체크 정도까지만 자동화 범위에 두고, 기획·카피·결정은 사람이 그대로 맡는 그림이다.
컴포넌트 도식
마케터의 질의가 들어오면 에이전트가 생각 → 도구 선택 → 도구 실행 → 결과 관찰의 ReAct 루프를 돌면서 답을 만든다. 사용하는 도구는 세 가지면 충분하다 - 사내 지식을 찾는 rag_search, 외부 트렌드·경쟁사를 찾는 web_search, 생성된 카피를 검증하는 compliance_check.
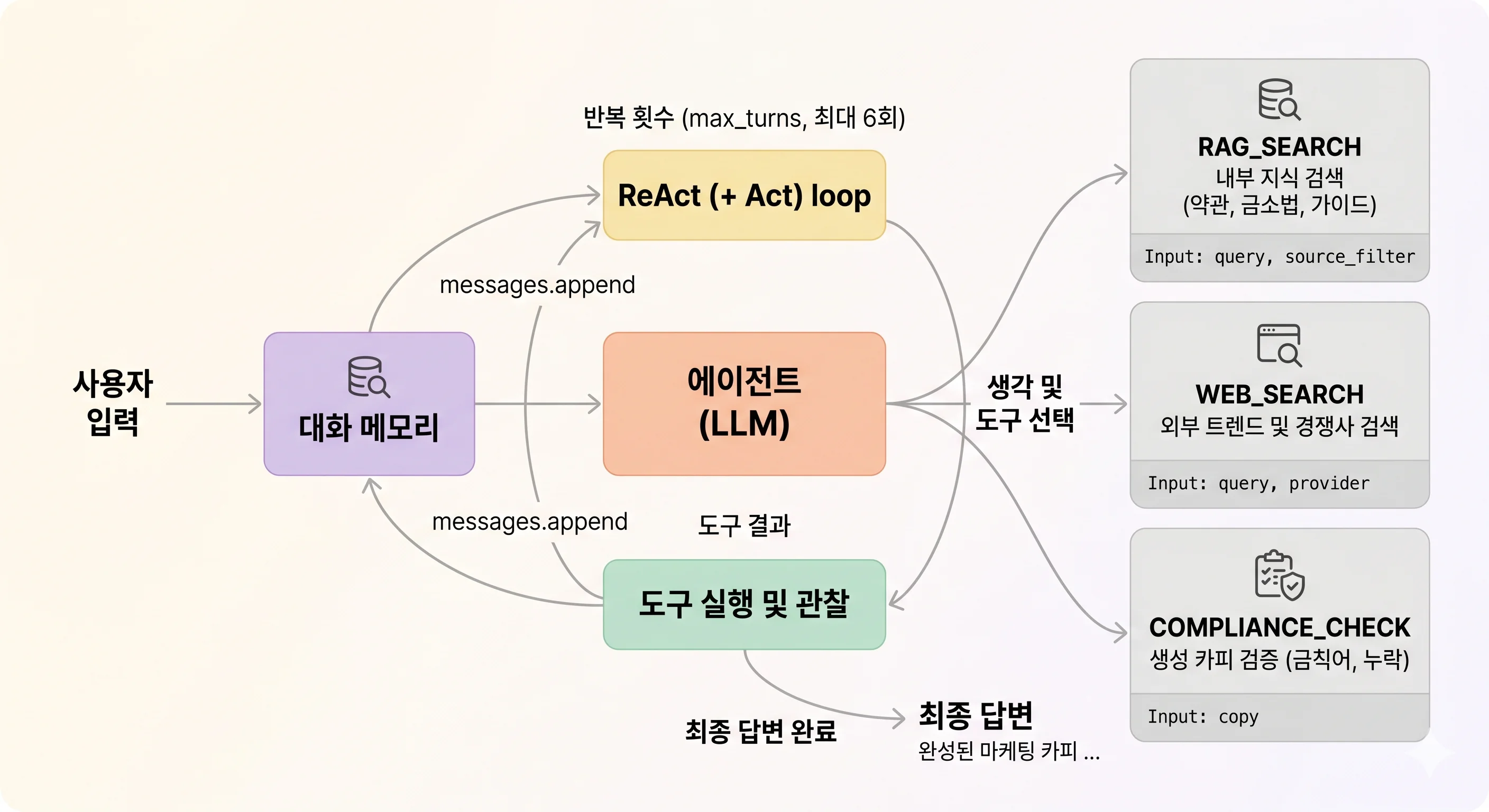
이 단계의 핵심은 “무엇을 자동화하지 않는가” 다. 카피 작성, 컨셉 결정, 매체 선택 같은 산출물 책임이 무거운 일은 모두 사람이 그대로 맡는다. AI는 흩어진 정보를 모아 주는 비서 역할에 한정된다.
비용 구조의 결
이 단계에서 LLM·웹 서치·임베딩 같은 변동비는 마케터 인건비 대비 작은 편이라는 게 일반적인 감각이다. 도입 의사결정의 변수는 보통 한국 금융사 특유의 보안 검토·내부 통제 협의 비용 쪽이 변동비를 넘어서곤 한다는 점에 가깝다.
한계 - 어디서 무너지는가
시나리오 1. 표가 많은 카드 약관에서 RAG가 헛소리할 때. “프리미엄 카드 연회비 면제 조건”을 물었을 때, 셀 병합된 표가 평탄화되면서 다른 카드 등급 행과 섞여 retrieval되면 LLM은 그럴듯하지만 약관과 다른 답을 합성할 수 있다. 이 단계에서는 “수치·조건 답변은 원문 인용 + PDF 페이지 링크”를 강제하는 우회로 어느 정도 막아두지만, 근본 해결은 Phase 2 이상의 Document Parse 기반 ETL 쪽으로 넘어가는 그림에 가깝다.
시나리오 2. 법령 개정 직후 폐지 조항을 인용할 때.
시행령 개정 시점과 인덱싱 배치 주기 사이의 갭에서 폐지 조항이 살아 있을 위험이 생긴다. effective_date 필터로 부분 차단되지만, 개정 시점 자체를 자동 감지하기 어렵다는 점이 구조적 한계로 남는다.
시나리오 3. Agent가 web_search 결과를 사실로 단정할 때. 종료된 경쟁사 프로모션이 “현재 운영 중”으로 합성될 가능성이 있다. 자사 카피에 “경쟁사 대비 우위” 문구로 옮길 경우 표시광고법상 부당한 비교광고 리스크가 따라올 수 있다. 단일 Agent로는 출처 freshness와 authority를 자체 판단하기 어려워, Phase 2에서 도메인 화이트리스트와 게시일 패널티 같은 장치로 보완하는 흐름이 자연스럽다.
Phase 2 - Planning Partner
사람이 결정한다, AI는 초안을 짠다.
이 단계의 본질은 역할별 에이전트가 협업하면서, 사람이 결정 게이트에 들어가는 구조다. 리서치를 넘어 상품 분석·USP 도출·카피 초안·채널 믹스까지 AI가 초안을 만들고, 사람은 정해진 몇 곳에서 선택·수정·승인을 맡는다.
구현 프레임워크는 여러 후보가 있겠지만, 이 글에서는 CrewAI를 예시로 풀어 본다. CrewAI는 Role/Task/Process 추상화로 마케팅 팀 구조를 자연스럽게 매핑할 수 있고, HITL을 native로 지원해 학습곡선이 비교적 낮은 편이다(대안으로 AutoGen, LangGraph 단독 등도 가능 - Phase 3에서 LangGraph로 확장하는 그림과도 호환된다).
컴포넌트 도식
브리프가 들어오면 정보 수집 레이어 5개 에이전트가 병렬로 자료를 모은 뒤, 컨셉 합성 → HITL Gate 1(컨셉 선택) → Copywriter → Compliance Critic 검수 → HITL Gate 2(카피 선택) → Media Planner → 최종 Critic → HITL Gate 3(예산 승인) 순으로 흐른다. 사람의 결정 게이트가 세 곳, 컴플라이언스 검수는 cross-cutting으로 두 곳에 깔린다.
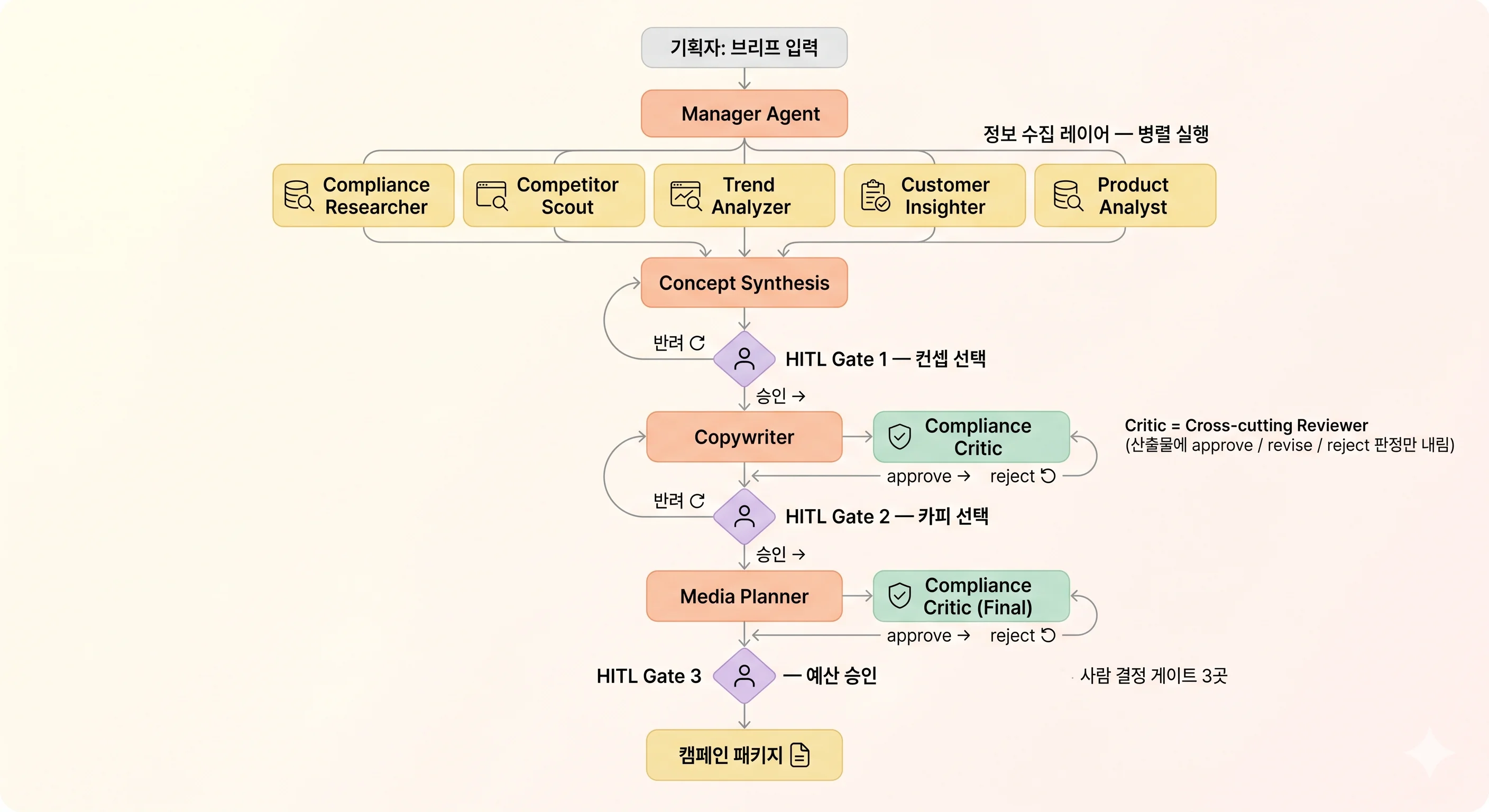
눈여겨볼 만한 패턴 세 가지
1. 정보 수집은 병렬, 결정 단계는 위계 - 결을 섞어 쓰기. 정보 수집 레이어는 서로 의존이 없어 병렬로 흘려도 무리가 없는 반면, 컨셉·카피·미디어 단계는 Critic이 위반을 발견했을 때 작성자로 되돌려 재작성하는 루프가 필요해진다. 그래서 두 결을 섞어 쓰는 구성이 도메인 특성과 비교적 잘 맞는 편이다 - CrewAI의 Sequential/Hierarchical Process를 조합하는 방식도 있고, 별도 워크플로우 엔진을 얹는 방식도 가능하다.
2. HITL은 한 번에 끝까지 가지 않게. HITL을 풀어 놓는 방식은 여러 갈래가 있다. CrewAI의 기본 human input 옵션처럼 단순하게 두는 방식도 있고, CrewAI Flows나 LangGraph 같은 흐름 제어 도구를 얹어 비동기 승인 큐로 구성하는 방식도 있다. 어느 쪽을 고르든 핵심은 도구 선택보다 - 단위 작업 사이에 사람 결정 구간을 비동기로 끼워 넣어 며칠 단위 검토도 자연스럽게 흡수되도록 두는 것 에 가깝다.
3. Compliance Critic은 Cross-cutting Reviewer.
Critic은 자체 산출물을 만들지 않고, 다른 에이전트의 결과물에 approve / revise / reject 셋 중 하나의 판정을 내리는 역할에만 집중한다. reject가 나오면 작성자로 돌려보내 재작성, 일정 횟수(예: 3회) 안에 통과하지 못하면 컨셉 단계로 escalate하는 가드를 함께 깔아 둔다.
비용 구조의 결
캠페인 1건당 LLM 변동비는 보통 사람이 체감하기 어려운 수준(수백 원~수천 원대)에 머무는 편이다. 이 단계에서 비용을 끌어올리는 주요 변수는 Critic 재작성 루프 횟수, Manager 위임 오버헤드, 모델 선택(정보 수집을 Haiku급으로 다운그레이드할지) 정도로 모이는 경향이 있다.
한계 - Phase 3로 넘어가야 하는 신호
시나리오 1. 상태 지속성이 약하게 느껴질 때. 카피 게이트에서 기획자가 24시간 자리를 비운 사이 서버 재배포로 Crew 프로세스가 죽으면, 중간 산출물의 영속화·재개 의미론을 직접 구현해야 하는 부담이 생긴다. 컨텍스트 누락 시 처음부터 재실행돼 토큰 비용도 함께 부풀어 오를 수 있다.
시나리오 2. 이벤트 드리븐 트리거가 필요해질 때. 새 가이드라인이 발표돼 진행 중인 캠페인 다수의 카피를 한꺼번에 재검토해야 하는 상황이라면, 명시적 kickoff() 호출 기반 pull 모델만으로는 외부 이벤트를 받아 어떤 Crew를 어떤 컨텍스트로 깨울지 라우팅하는 레이어가 비어 있다고 느끼기 쉽다.
시나리오 3. Cross-Campaign Learning이 아쉬워질 때. 누적 캠페인이 쌓일수록 “20대 여성 신용대출은 ‘한도’보다 ‘간편’ 키워드가 CTR 1.8배” 같은 패턴이 보이기 시작하는데, CrewAI Long-term Memory는 Task output retrieval 수준에 가깝다 보니 회고적 학습 메커니즘으로 끌어 쓰기는 다소 부족하게 느껴질 수 있다.
이런 신호가 누적될 즈음 Phase 3로의 진화를 검토해 보면 자연스럽다.
Phase 3 - Autonomous Squad
AI가 굴린다, 사람은 거버넌스를 본다.
이 단계의 본질은 AI끼리 결과를 주고받기 시작하는 구조다. 브리핑 한 줄에서 출발해 Research → Planning → Production → Ops로 이어지는 캠페인 풀사이클을 시스템이 굴리고, 사람은 거버넌스 게이트와 예외 처리만 본다. 구성 요소를 한 가지 예시로 그려 보면 - 매크로 오케스트레이터(LangGraph, Temporal, Inngest, Prefect 등)가 흐름을, sub-crew(CrewAI, AutoGen, 커스텀 멀티 에이전트 등)가 팀별 협업을, 메모리 레이어(Mem0, Zep, Letta 등)가 캠페인 간 학습을, Observability(Langfuse, LangSmith, Arize Phoenix 등)가 trace·eval을 맡는 식이다. 어느 조합이 정답이라기보다, 조직의 운영 환경·보안 제약·기존 스택과 맞는 결을 찾아가는 쪽에 가깝다.
컴포넌트 도식
전체 시스템을 Control Plane / Data Plane / Observability Plane 의 3-Plane으로 분리하는 구획이 자주 거론된다. 금융권에서 흔히 요구되는 망 분리와 감사 추적 정책과 자연스럽게 맞아떨어지는 형태다.
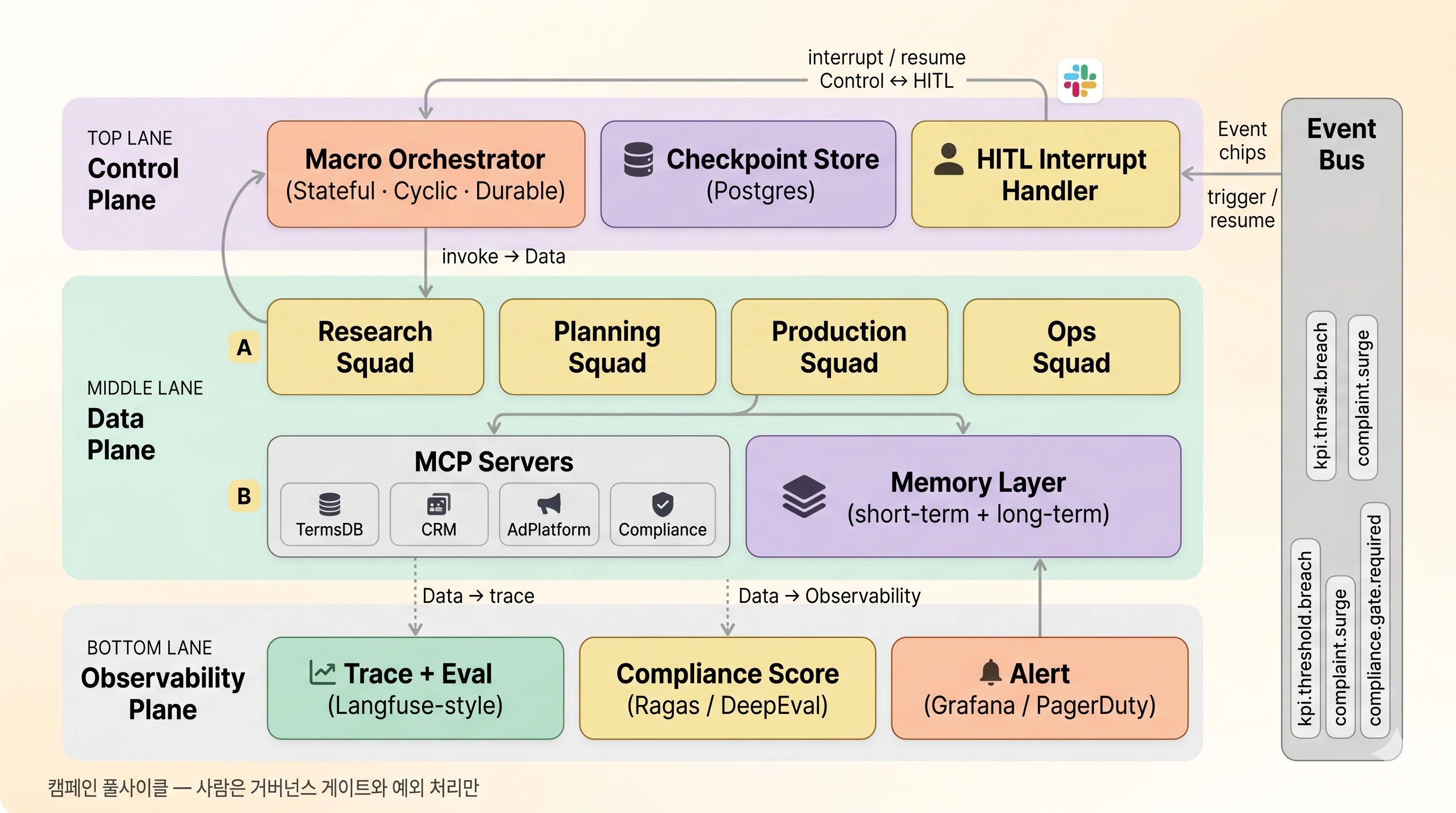
| Plane | 책임 | 장애 시 영향 |
|---|---|---|
| Control | Flow 상태·순서·체크포인트 | 신규 캠페인 진입 불가, 기존은 checkpoint 복구 |
| Data | LLM 호출·도구 실행·메모리 R/W | 해당 노드만 retry, graph는 유지 |
| Observability | trace·eval·alert | 가시성만 저하, 실행은 무영향 |
눈여겨볼 만한 패턴 네 가지
1. Stateful + Cyclic + Durable Orchestration. 캠페인이 며칠~몇 주 단위로 돌아가는 만큼, 단순 DAG가 아닌 상태가 영속화되고 루프를 표현할 수 있는 매크로 오케스트레이션이 필요해진다. 법무 검토가 이틀 걸려도 graph 상태가 유지되어야 하고, “KPI 미달 시 Planning으로 되돌아가기” 같은 루프가 자연스럽게 표현되어야 한다. 이 자리에 들어갈 만한 도구로는 LangGraph 외에도 Temporal, Inngest, Restate, Prefect 같은 워크플로우 엔진들이 거론된다 - 어느 쪽을 고르든 상태 영속화·재개·루프라는 세 요건을 충족하는지를 기준으로 보면 된다.
2. Cross-Campaign Learning - 다음 캠페인이 지난 교훈을 본다.
캠페인 종료 시점에 Reflection 단계가 KPI·민원·blocker에서 “교훈 후보”를 추출하고, 다음 캠페인이 시작되면 관련 교훈을 회상해 brief에 주입하는 흐름이다. 회상 방식은 갈래가 여러 개다 - 단순 의미 검색만으로 가는 방식, 메타데이터 필터(product, segment, category 등)를 함께 거는 방식, 캠페인 단위 요약을 별도로 키우는 방식, 더 나아가 RLHF/DPO 같은 학습 루프로 정책 자체를 업데이트하는 방식까지. 적금 캠페인에 카드 캠페인 교훈이 섞이는 사고가 종종 보고되는 만큼, 회상 결과의 적합성을 어떻게 거를지가 도구 선택보다 먼저 결정해야 할 부분에 가깝다.
3. 사내 시스템을 표준 도구로 감싸기. 약관 DB, CRM, 광고 플랫폼, 컴플라이언스 체크 같은 사내 시스템을 도구 표준으로 감싸 두면, 어떤 오케스트레이터·에이전트 프레임워크에서든 동일 인터페이스로 호출하기 쉬워진다. 표준화 방식의 한 갈래로 MCP(Model Context Protocol)가 자주 거론되고, OpenAPI 기반 tool spec, gRPC, 직접 API 추상화 같은 접근도 충분히 가능하다. 어느 쪽을 고르든 사내 시스템을 굴릴 때는 다섯 가지 원칙이 함께 따라오는 편이다.
- 읽기 전용 우선 - 광고 게재 같은 쓰기는 별도 도구로 분리해 권한 관리
- Row-level Security 적용 - DB 사용자는 마케팅 부서 가시 범위만 SELECT
- 모든 호출 → 감사 로그 - caller, args, result hash 기록
- 버전 명시 -
effective_date로 어느 시점 약관을 봤는지 재현 가능 - PII 마스킹 - CRM 계열 도구는 주민번호·계좌번호 평문 반환을 차단
4. 이벤트 트리거 자동 흐름은 어디까지 둘지. KPI 임계 미달이나 민원 급증 같은 이벤트가 발생하면 매크로 오케스트레이터가 진행 중인 캠페인 흐름을 다시 깨워 재집행할 수 있다. 어디까지 자동으로 두고 어디부터 사람을 다시 끼울지는 정답이 없는 영역인데, 한 가지 결로는 재집행이 Planning 단계까지만 자동으로 되돌아가도록 두고, Production 이후 단계는 다시 Compliance Gate를 거치게 두는 방식이 자주 거론된다. 자동 루프가 컴플라이언스 게이트를 우회하지 못하게 그래프 자체에 가드를 박아 두는 셈이다.
메모리 레이어 후보 비교
| 항목 | Mem0 | Zep | Letta |
|---|---|---|---|
| 코어 컨셉 | LLM 추출 fact 저장 | Temporal Knowledge Graph | Self-editing agent memory |
| 운영 부담 | 낮음 (Qdrant + Postgres) | 중간 (Neo4j 또는 graph store) | 중간~높음 |
| 금융권 적합성 | 단순·감사 용이 | graph 운영 부담 | 거버넌스 충돌 가능성 |
금융권 거버넌스 + 운영 단순성을 우선시한다면 Mem0 self-host 가 1순위 후보로 자주 거론된다. 고객 단위 시계열 분석이 핵심으로 떠오르면 Zep을 보조로 얹는 그림도 가능하다.
Pre-launch Compliance Gate UX (Slack 예시)
[Pre-launch Compliance Gate] Campaign #42 - 30대 직장인 정기적금
─────────────────────────────────
Compliance Score: 0.87 (Ragas faithfulness 0.91)
Blockers: 없음
Warnings:
· "최고 연 5%" → 우대조건 별도 표기 필요
· 예금자보호 문구 위치 (footer → body 권장)
Recall된 과거 학습:
· 2026-Q1: "월 이자" 표현 CTR 18% 우위
· 2025-Q4: 비슷한 문구로 민원 3건
[Approve] [Request Revision] [Reject]
─────────────────────────────────
※ 승인은 2인 (법무 1 + 컴플라 1) 필요. 24h 내 미응답 시 자동 Reject.비용 구조의 결
이 단계로 오면 비용 구조가 LLM보다 인프라·운영 도구 쪽으로 무게중심이 옮겨가는 경향이 있다. 캠페인 수가 늘어도 한계비용이 선형으로 따라오지는 않아, 일정 규모까지는 동일 인프라로 흡수되곤 한다. 단 컴플라이언스 인력 시간은 이 그림 바깥에 있는 별도 항목이며, 실제 TCO를 좌우하는 변수가 되곤 한다는 점은 짚어 둘 만하다.
거버넌스 체크리스트
| 영역 | 항목 | 어디서 |
|---|---|---|
| 감사 로깅 | 모든 노드 진입·종료 기록 | 오케스트레이터 audit_log (append-only) |
| 감사 로깅 | LLM prompt·completion 보존 | Observability 도구 보존기간 정책 |
| 감사 로깅 | 사내 도구 호출 입력·출력 hash | MCP 미들웨어 |
| 감사 로깅 | HITL 승인자·시각 | Compliance Gate audit |
| 데이터 격리 | 캠페인 간 단기 메모리 분리 | 캠페인 단위 key prefix |
| 데이터 격리 | 고객 PII는 에이전트 컨텍스트 진입 금지 | CRM MCP 마스킹 |
| 권한 분리 | Read 도구 / Write 도구 분리 | 별도 인증 컨테이너 |
| 사고 대응 | Kill switch - 일괄 정지 | Event Bus system.halt |
| 사고 대응 | Rollback - 직전 승인본 복귀 | Creative versioning |
Ceiling - 자동화의 경계
자동화하기 어려운 영역을 명시해 두는 일이 거버넌스 관점에서는 본 자동화 흐름만큼이나 중요하게 다뤄지곤 한다. “완전 자동화 마케팅”이라는 표현을 굳이 피해 둔 이유다.
| 영역 | 자동화 불가 이유 | 본 시스템 처리 |
|---|---|---|
| 협회 사전심의 | 외부 기관 사람이 사람의 검토로 진행 | 제출 패키지 자동 생성까지만 |
| 신상품 런칭 | 약관 미확정·규제 해석 모호 | Phase 3 자동 흐름 제외, Phase 2로만 |
| 민감 이슈 대응 광고 | 경영진·홍보실 정성 판단 | Event Bus가 감지하면 자동 흐름 정지, 매뉴얼 모드 |
| 개인 맞춤 추천 카피 | 신용정보법·개인정보보호법 동의 범위 | 세그먼트 단위까지만 |
시스템 본질에 가까운 한계도 다섯 가지 정도가 자주 거론된다.
- 메모리 누적의 양날 - Mem0가 누적한 “교훈”이 잘못된 일반화를 강화할 수 있어 분기 단위 메모리 큐레이션을 같이 굴리는 게 안전한 편
- HITL 의존도 - Compliance Gate와 Exception Escalation 두 곳에 사람이 묶여 있는 구조라, 검토자 부재 시 throughput이 빠르게 떨어질 수 있음
- 모델 비결정성 - 동일 입력에 동일 출력을 보장하지는 않아, 재현성은 trace 보존으로 사후 확인하는 식으로 풀게 됨
- 외부 시스템 SLA - 광고 플랫폼 API 변경, 사내 약관 DB 스키마 변경 시 MCP가 단일 실패점이 될 가능성
- 컴플라이언스 비용은 크게 줄지 않는다 - 자동화는 검토 대상의 양과 일관성을 늘려 주지만, 책임 자체는 여전히 사람에게 남음
이런 그림에서 ROI는 “검토 업무의 효율” 쪽이라기보다는 기획·제작 사이클 단축 쪽에서 회수되는 흐름으로 보는 게 자연스럽다.
Cross-Phase 체크포인트
| 질문 | 한 가지 시각 |
|---|---|
| 어디서 시작해 보는 게 좋을까? | Phase 1 - 리서치 자동화부터. 단기간에 PoC를 시도해 볼 만한 범위 |
| Phase 2를 검토할 만한 신호? | 마케터가 카피 초안 작성에 시간을 적지 않게 쓰고 있을 때 |
| Phase 3를 검토할 만한 신호? | 며칠 단위 캠페인 lead time, 외부 이벤트 자동 대응 필요, 누적 학습 데이터가 의미 있게 쌓였을 때 |
| 한국 금융사 보안 제약 어디부터? | 국내 리전 LLM 또는 망분리 환경 LLM → 사내 임베딩 → 사내 도구 RLS 순으로 살펴보면 무난 |
| 모델 선택의 출발점? | Phase 1은 상위 모델, Phase 2·3 정보 수집은 저비용 모델 다운그레이드도 옵션 |
| 어디서 자주 막히곤 하나? | Phase 2의 HITL - CLI 입력 방식으로 시작했다 운영 적합성 문제로 재설계되는 경로가 흔히 보임 |
| ROI는 어디서 보이나? | 리서치 시간 단축, 기획 lead time 단축, 마케터 1인이 다루는 캠페인 수 확장 - 단계마다 다른 결로 |
닫는 글 - 자동화의 끝이 아닌 자동화의 경계
Phase 3 시스템도 결국 마케팅 사이클 단축과 일관성 확보를 위한 도구에 가깝지, 컴플라이언스 책임을 위임받는 자리에 놓이지는 않는다. 두 개의 HITL 게이트는 우회 대상이 아니라 시스템이 기대는 안전장치이며, 거버넌스 관점에서는 “자동화의 끝”이라기보다 “자동화의 경계”를 그려 두는 역할에 가깝다.
한국 금융사에서 멀티 에이전트 도입은 결국 권한과 책임의 재설계라는 결로 이어지는 경우가 많다. Phase 1은 도구 선택의 문제, Phase 2는 팀 구성의 문제, Phase 3은 운영체계의 문제 - 단계마다 풀어야 할 결이 달라진다는 점이 이 로드맵의 진짜 메시지에 가깝다.
그리고 이 영역에는 정답이 한 가지인 구조가 없다. 이 글에 등장한 도구·구조·패턴은 모두 한 가지 시각의 예시이고, 같은 결을 다른 갈래로 푸는 방식이 훨씬 더 많다. 이 글이 다음 PoC 회의에서 화이트보드 위에 그려 볼 첫 번째 다이어그램이 될 수 있다면 충분하다 - 두 번째, 세 번째 다이어그램은 조직마다 결국 다르게 그려질 것이기 때문에.
관련 글

내가 구축한 메모리 시스템이 Claude Code 내부와 닮아있었다
CC 내부 Memory System(4타입 영구 메모리, Auto-Dream, Auto-Compact)과 독립 구축한 3-Layer 시스템(문서→인덱스→시맨틱검색)의 구조적 대응. validate_placement()는 CC에 없는 차별점

에이전트를 어떻게 조직하는가 - Hierarchy·Graph·Swarm·Routing과 회의론
쪼갠 에이전트를 어떻게 조직할 것인가. 네 가지 구조를 살펴보면서 'LLM 스웜은 사실 스웜이 아니다'라는 회의적 논문 한 편을 함께 본다. 결국 구조 선택은 가격에 끌려간다는 게 결론. 시리즈 2편.

52개 도구, 23단계 보안: 에이전트 Tool System의 실제
52개 빌트인 도구의 공통 인터페이스, 10단계 실행 파이프라인, 안전=병렬/위험=순차 동시성 모델, 5단계 권한 파이프라인, 888KB 23단계 bash 보안