
Multi-Agent for Korean Financial Marketing - A Phased Sketch
Korean financial advertising is reported to take more than a month per campaign on average, and a non-trivial share of that time tends to go into research and review. Campaigns have to clear the Financial Consumer Protection Act (금소법), the Act on Fair Labeling and Advertising, and the self-regulatory guidelines of industry associations (Credit Finance Association, Life Insurance Association, Financial Investment Association, etc.), all while marketers cross-check competitor campaigns, Naver search trends, internal product terms, and previously approved copy (note: I haven’t worked in this industry myself, so practitioners’ corrections on the specifics are welcome).
In a structure like this, multi-agent systems look attractive on paper, but teams that try to build the full stack in one go often get stuck at the same place - who has the authority to decide what gets blurry.
This piece sketches one way to avoid that trap, through a phased approach. Phase 1 is the tool, Phase 2 is the colleague, Phase 3 is the squad - authority is handed over gradually, in stages. Each phase comes with a component sketch, a few patterns worth watching, and the limits where it tends to break. This is held throughout as one example scenario; the starting point, scope, and pace will look different for every organization.
A Marketer’s Workflow - One Example
It helps to lay out what a person actually does, before deciding what to automate. The shape varies by company, sector, and product, but here is one way to picture how a single financial advertising campaign moves through a planning team:
| Phase | Step | Key Input | Key Output |
|---|---|---|---|
| Briefing | Define campaign objective | Business unit request, quarterly KPI | Goal, budget, timeline |
| Briefing | Understand product spec | Terms, comparison disclosures | Rate, limit, fees, risk factors |
| Research | Regulatory scan | FCPA, association guidelines, FSS advisories | Mandatory-disclosure & prohibited-term checklist |
| Research | Competitor benchmark | Web, YouTube, social, search ads | Message · tone · channel matrix |
| Research | Trend analysis | Naver DataLab, communities | Rising keywords, issues |
| Research | VoC & persona | CRM, call center, reviews | Pain points, needs |
| Planning | Concept | All upstream inputs | 2-3 concept candidates |
| Planning | Copy & CTA | Concept, USP, persona | Headlines, sub-copy, mandatory disclosures |
| Planning | Channel mix | Budget, channel fit | Per-channel KPI · budget |
| Review | Self-compliance check | Copy + regulatory checklist | Risk report |
| Review | Legal & compliance review | First-pass version | Revision notes |
| Review | Association pre-review | Final creative | Approval or revision request |
| Launch | Distribution & monitoring | Live data | Real-time performance, complaint alerts |
| Launch | Post-mortem | Performance data | Inputs for the next campaign |
Once you lay it out this way, the regions where automation fits relatively well tend to cluster around research (regulatory scan, competitor benchmark, trends) and self-compliance, while the decision gates that stay with humans are most often campaign-objective definition, concept selection, and legal sign-off.
The Phased Approach as a Lens
Trying to move this entire flow onto multi-agents at once usually breaks in two places. First, where humans and AI hand off authority gets blurry. Second, compliance has to live inside the flow, not after it - and that constraint is hard to handle if the system is designed for end-to-end autonomy from day one. The more you try to solve both at once, the heavier the system gets, and the more often it stalls in actual operation.
The alternative is to split automation scope and human decision rights into stages. Start with research and information-gathering (where the output carries lighter responsibility), add explicit HITL gates the moment AI starts producing creative artifacts, and only consider fully autonomous agent-to-agent loops at the end.
One Example - A Three-Phase Scenario
The table below sketches that staged approach as one example. Real organizations may draw the lines differently, and staying at one phase often makes more sense than pushing toward the next.
| Phase | Automation scope | Human role | Stack, in one line |
|---|---|---|---|
| 1 | Research + self-compliance | Almost all planning, writing, deciding | RAG agent + a few tools |
| 2 | Research + planning drafts + copy + channel mix | Decisions at a few gates | Collaborative multi-agent + HITL |
| 3 | Most of the pipeline + post-mortem learning + event-driven response | Governance & exception handling | Macro orchestrator + memory layer + observability |
The qualitative shifts between the three phases can be summarized as two thresholds. The threshold between Phase 1 and 2 is “AI starts producing artifacts” - once it does, accountability becomes blurry, and HITL (Human-in-the-Loop) gate design effectively becomes governance design. The threshold between Phase 2 and 3 is “AI agents start exchanging artifacts with each other” - Critic agents gain the authority to reject Copywriter outputs, and the authority hierarchy across agents has to be re-drawn.
Phase 1 - Research Co-pilot
The human writes; the AI gathers.
This stage can start fairly light. One example of a setup is a single RAG block + a few tools + a ReAct loop, but a simpler workflow automation or a notebook-based LLM helper would also be a perfectly reasonable starting point. Either way, automation stays at research and self-compliance checking; planning, copywriting, and decisions remain entirely with the human.
Component Sketch
When a marketer issues a query, the agent runs a ReAct loop of think → choose tool → execute tool → observe result until it converges on an answer. Three tools are usually enough - rag_search for internal knowledge, web_search for external trends and competitors, and compliance_check for verifying generated copy.
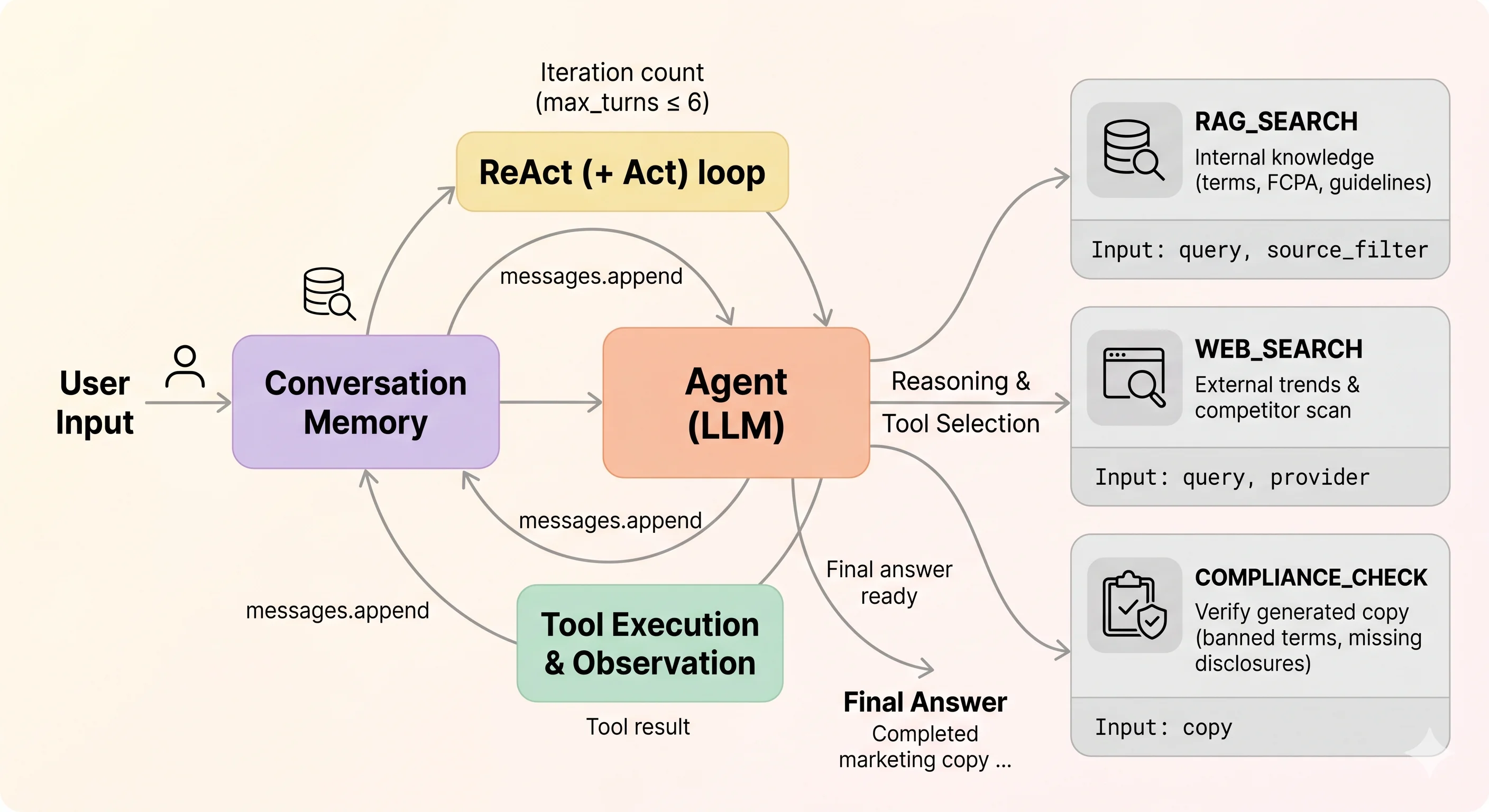
The point of this stage is what you choose not to automate. Copywriting, concept selection, channel choice - anything where the artifact carries real responsibility - stays with the human. The AI’s role is bounded: an assistant that gathers scattered information.
What the Cost Profile Looks Like
At this stage, the variable costs (LLM calls, web search, embeddings) tend to be small relative to a marketer’s salaried hours. The real variable in the adoption decision, in the Korean financial context specifically, is often the security review and internal-control coordination cost, which can easily exceed the variable cost.
Limits - Where It Starts to Break
Scenario 1. RAG hallucinating on table-heavy card terms. When asked about something like “annual fee waiver conditions for the premium card,” merged-cell tables can be flattened during parsing and rows from different card tiers may end up retrieved together, producing a plausible-sounding answer that doesn’t match the actual terms. This stage handles it via a guardrail like “always cite source text + link to the PDF page for any answer involving numbers or conditions,” but the deeper fix usually moves toward Phase 2 territory - Document Parse-based ETL, structured extraction.
Scenario 2. Citing a clause that has just been repealed.
There’s a gap between when a regulation is amended and when the index batch picks it up. An effective_date filter blocks part of the issue, but detecting the moment of amendment itself is harder to automate, and that tends to remain a structural limit.
Scenario 3. The agent treating web search results as ground truth. A discontinued competitor promotion can get synthesized as “currently active.” If a marketer copies a “we beat competitor X” line into their own campaign, this can drift into unfair-comparison territory under labeling/advertising law. A single agent isn’t well-positioned to judge source freshness and authority on its own; in practice, Phase 2 typically adds domain whitelists and recency penalties.
Phase 2 - Planning Partner
The human decides; the AI drafts.
The shape of this stage is role-specific agents collaborating, with humans inserted at decision gates. AI starts drafting product analysis, USP candidates, copy, and channel mix; humans select, edit, and approve at a few defined points.
There are several framework choices for implementation; this piece uses CrewAI as one example. CrewAI’s Role/Task/Process abstractions map fairly cleanly onto a marketing team structure, and HITL is supported natively, which keeps the learning curve lower for early prototyping (alternatives like AutoGen or LangGraph alone are equally reasonable - and would compose naturally with the Phase 3 setup below).
Component Sketch
A brief enters the system, five information-gathering agents work in parallel, then the flow narrows: concept synthesis → HITL Gate 1 (concept) → Copywriter → Compliance Critic review → HITL Gate 2 (copy) → Media Planner → final Critic → HITL Gate 3 (budget). Three human decision gates; two cross-cutting Critic checkpoints.
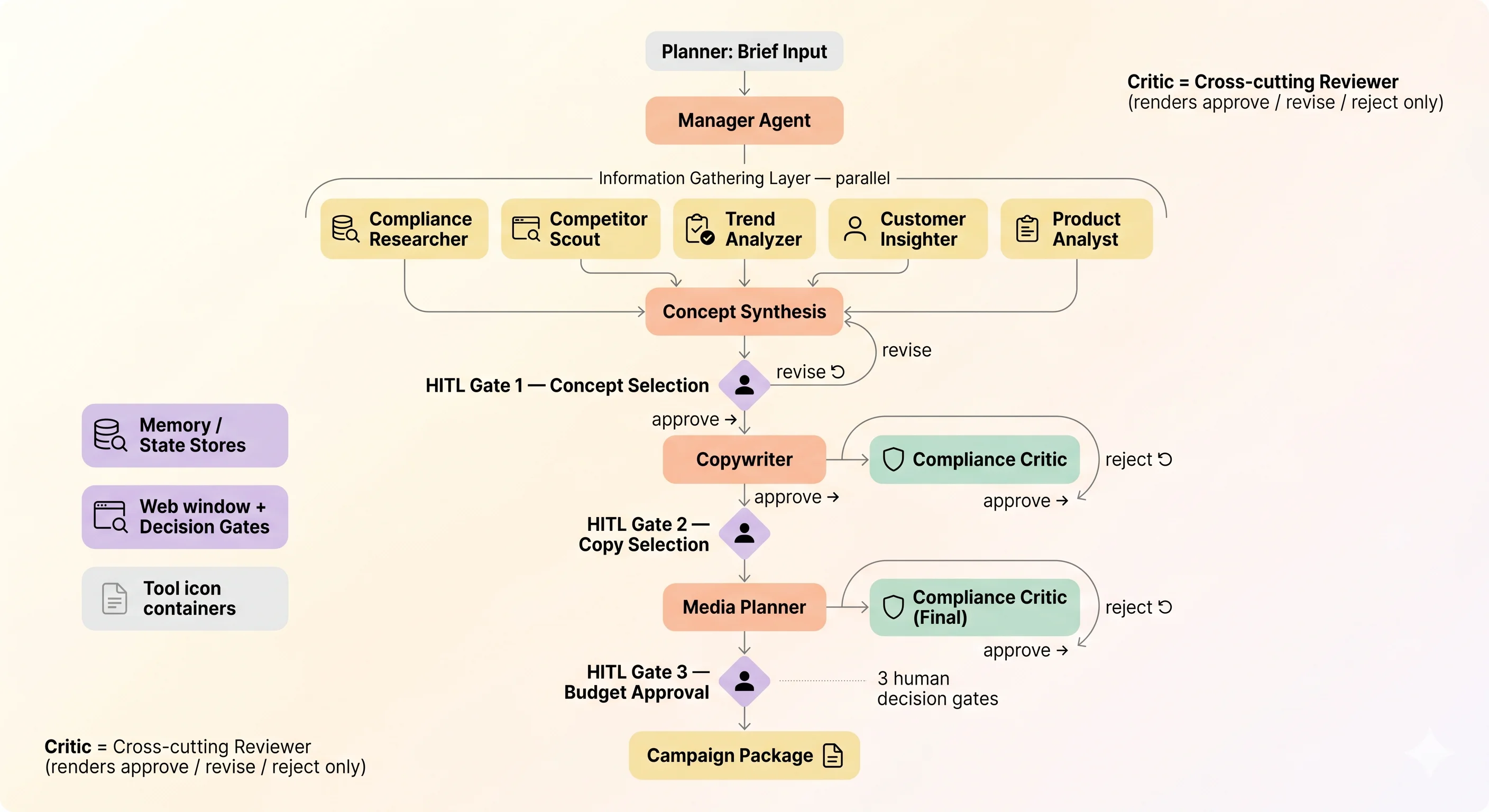
Three Patterns Worth Watching
1. Parallel for gathering, hierarchical for decisions - mixing the textures. The information-gathering layer has no internal dependencies, so running it in parallel works fine. The concept/copy/media stages, however, need a loop that can route artifacts back to the writer when the Critic flags a violation, so a hierarchical texture fits better there. Mixing the two textures matches the domain reasonably well - CrewAI’s Sequential/Hierarchical Process can be combined, or a separate workflow engine can sit on top.
2. Don’t try to run HITL end-to-end in one go. There are several ways to handle HITL. Simple options like CrewAI’s built-in human input exist, and more elaborate setups using flow controllers like CrewAI Flows or LangGraph to wire up async approval queues are also viable. The point isn’t really the tool choice - it’s the principle: insert human decision points asynchronously between units of work, so multi-day reviews can be absorbed without breaking the run.
3. Compliance Critic as a cross-cutting reviewer.
The Critic doesn’t produce its own artifacts. It reviews other agents’ outputs and renders one of three verdicts - approve / revise / reject. On reject, the writer takes another pass; if a configurable retry budget (say, three rounds) is exhausted, the flow escalates back to the concept stage rather than continuing to push forward.
What the Cost Profile Looks Like
Per-campaign LLM variable cost at this stage usually stays at a level that’s hard for a person to feel directly (anywhere from a fraction of a dollar to a few dollars). What pushes the cost up tends to come from a small set of variables: how many Critic rework rounds occur, how much manager-delegation overhead accumulates, and which models are chosen (downgrading the gathering layer to a Haiku-class model is a typical lever).
Limits - Signals That Phase 3 Is Worth Considering
Scenario 1. State persistence starts to feel fragile. A planner steps away for 24 hours at the copy gate; the server redeploys; the Crew process dies. Persisting and resuming intermediate artifacts becomes something you have to build yourself, and missing context can mean re-running the whole pipeline (which inflates token cost too).
Scenario 2. Event-driven triggers become necessary.
When a new regulatory guideline is issued and the copy across multiple in-flight campaigns needs to be re-reviewed at once, an explicit-kickoff()-only pull model starts to feel thin - there’s no routing layer for “external event arrives, wake the right Crew with the right context.”
Scenario 3. Cross-campaign learning becomes desirable. As campaigns accumulate, patterns like “for women in their 20s borrowing personal loans, the keyword ‘simple’ outperforms ‘limit’ on CTR by 1.8x” start surfacing. CrewAI’s Long-term Memory is closer to Task-output retrieval than to a learned policy, so pulling these patterns through as a retrospective learning mechanism feels somewhat under-equipped.
When several of these signals start stacking, looking at Phase 3 makes sense.
Phase 3 - Autonomous Squad
The AI runs the loop; humans look at governance.
The defining shape here is AI agents starting to exchange results among themselves. The system runs the full Research → Planning → Production → Ops cycle from a single brief, while humans focus on governance gates and exception handling. As one example composition - the macro orchestrator (LangGraph, Temporal, Inngest, Prefect, etc.) handles flow, sub-crews (CrewAI, AutoGen, custom multi-agent setups) handle team-level collaboration, the memory layer (Mem0, Zep, Letta, etc.) accumulates learning across campaigns, and observability (Langfuse, LangSmith, Arize Phoenix, etc.) handles trace and eval. There’s no single right combination here; the question is closer to which textures fit the organization’s operating environment, security constraints, and existing stack.
Component Sketch
A common partition splits the system into Control Plane / Data Plane / Observability Plane. This 3-Plane shape happens to align reasonably well with the network segregation and audit-trail requirements common in financial environments.
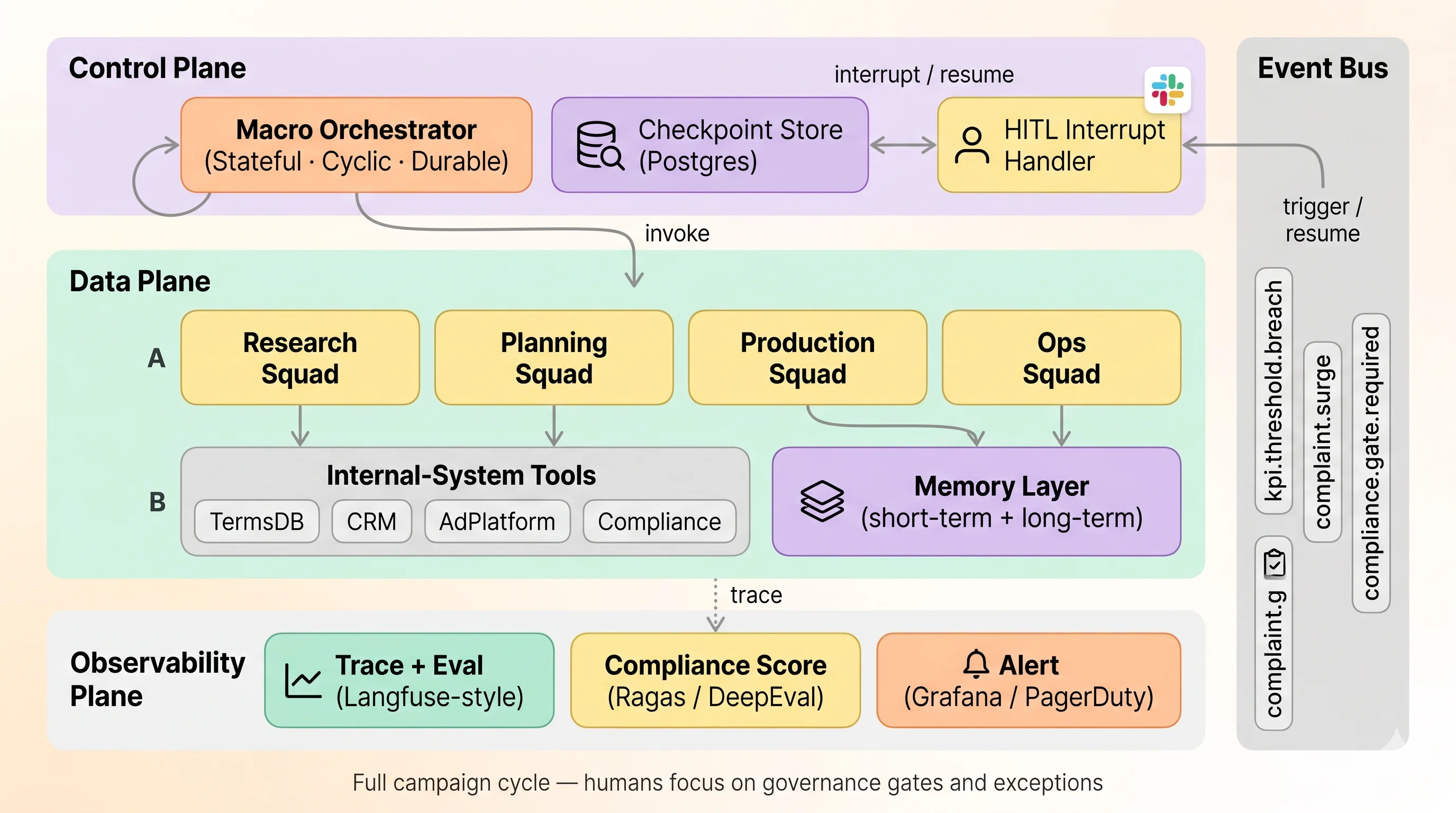
| Plane | Responsibility | Failure Impact |
|---|---|---|
| Control | Flow state, ordering, checkpoints | New campaigns can’t enter; existing ones recoverable from checkpoint |
| Data | LLM calls, tool execution, memory R/W | Failed node retries; graph stays intact |
| Observability | Trace, eval, alerts | Visibility degrades; execution unaffected |
Four Patterns Worth Watching
1. Stateful + Cyclic + Durable orchestration. Because campaigns run on a multi-day to multi-week timescale, the macro layer needs state persistence and the ability to express loops - not just a DAG. Graph state has to survive a two-day legal review, and “if KPI underperforms, return to Planning” should be naturally expressible. Tools that can sit here include LangGraph as well as Temporal, Inngest, Restate, Prefect, and similar workflow engines - the criterion is whether they satisfy the three requirements of state persistence, resumability, and loops.
2. Cross-campaign learning - letting the next campaign see the last one’s lessons.
At the end of each campaign, a Reflection step extracts “lesson candidates” from KPIs, complaints, and blockers; the next campaign recalls relevant lessons and injects them into the brief. There’s no single recall recipe here - pure semantic search, semantic search with metadata filters (product, segment, category), separately maintained per-campaign summaries, or even a learning loop like RLHF/DPO updating the policy itself. Given that lessons from a card campaign occasionally bleed into a deposit campaign, the more important question to settle is how to filter for relevance, ahead of which tool to pick.
3. Wrapping internal systems behind a tool standard. Wrapping internal systems (terms DB, CRM, ad platforms, compliance checks) behind a tool standard makes them callable through a consistent interface from any orchestrator or agent framework. One option is MCP (Model Context Protocol); OpenAPI-based tool specs, gRPC, or direct API abstractions are equally workable. Whichever route is taken, operating these systems in a financial context tends to bring along five recurring principles:
- Read-only first - write operations like ad placement go behind a separate tool with its own permission scope
- Row-level security - DB users see only what their team is supposed to see
- Every call → audit log - caller, args, result hash recorded
- Versioning -
effective_dateso you can reconstruct which version of the terms was visible - PII masking - CRM-side tools never return raw resident IDs or account numbers
4. How far should event-triggered automation run on its own. When events like KPI breach or complaint surge fire, the macro orchestrator can wake the in-flight campaign and re-execute. How far to let it run unattended, and where to insert humans again, is a question without one right answer. One commonly cited shape is to let auto re-execution roll back only as far as the Planning step, and require Production-onward steps to pass through the Compliance Gate again - a structural guardrail in the graph itself, so automation loops can’t quietly bypass compliance.
Memory Layer Candidates
| Item | Mem0 | Zep | Letta |
|---|---|---|---|
| Core concept | LLM-extracted fact storage | Temporal Knowledge Graph | Self-editing agent memory |
| Operational overhead | Low (Qdrant + Postgres) | Medium (Neo4j or graph store) | Medium-to-high |
| Fit for financial context | Simple and audit-friendly | Graph operation overhead | Possible governance friction |
For organizations weighting governance and operational simplicity, self-hosted Mem0 is the candidate that comes up most often. If customer-level temporal analysis becomes central, layering Zep alongside is a reasonable shape.
Pre-launch Compliance Gate UX (Slack example)
[Pre-launch Compliance Gate] Campaign #42 - Recurring Deposit, 30s Office Workers
─────────────────────────────────
Compliance Score: 0.87 (Ragas faithfulness 0.91)
Blockers: none
Warnings:
· "Up to 5% APY" - preferential conditions need separate disclosure
· Depositor protection notice placement (footer → body recommended)
Recalled prior lessons:
· 2026-Q1: "monthly interest" framing showed +18% CTR
· 2025-Q4: similar phrasing led to 3 customer complaints
[Approve] [Request Revision] [Reject]
─────────────────────────────────
※ Two approvers required (1 legal + 1 compliance). Auto-rejects after 24h of no response.Governance Checklist
| Area | Item | Where |
|---|---|---|
| Audit logging | Every node entry/exit recorded | Orchestrator audit_log (append-only) |
| Audit logging | LLM prompt/completion preserved | Observability tool retention policy |
| Audit logging | Internal-tool call input/output hash | Tool middleware |
| Audit logging | HITL approver & timestamp | Compliance Gate audit |
| Data isolation | Short-term memory separated per campaign | Per-campaign key prefix |
| Data isolation | Customer PII never enters agent context | CRM-side masking |
| Permission split | Read tools / Write tools split | Separate auth containers |
| Incident response | Kill switch - halt everything | Event Bus system.halt |
| Incident response | Rollback - return to last approved version | Creative versioning |
Ceiling - The Boundary of Automation
Naming what stays out of automation tends to matter as much, in a governance frame, as the automation flow itself. That’s why the framing here intentionally avoids the phrase “fully automated marketing.”
| Area | Why it doesn’t automate cleanly | What this system does instead |
|---|---|---|
| Association pre-review | An external body, reviewed by humans for humans | The system stops at packaging the submission |
| New product launches | Terms still in flux, regulation interpretation ambiguous | Excluded from Phase 3 auto flow; runs only as far as Phase 2 |
| Sensitive-issue ads (incidents, recalls) | Requires executive / PR judgment | Event Bus halts the auto flow on detection; switches to manual mode |
| Personalized recommendation copy | Credit Information Act / Personal Information Protection Act consent boundaries | Stays at the segment level; personalization handled elsewhere |
There are also five system-inherent limits that surface fairly often:
- The double edge of accumulated memory - the “lessons” Mem0 accumulates can reinforce wrong generalizations, so a quarterly memory curation cadence is safer to run alongside.
- HITL dependency - with humans tied to the Compliance Gate and Exception Escalation, throughput drops quickly when reviewers are unavailable.
- Model non-determinism - the same input doesn’t guarantee the same output, so reproducibility shows up as post-hoc trace inspection rather than guarantee.
- External system SLAs - ad platform API changes or internal terms DB schema changes can turn the tool layer into a single point of failure.
- Compliance cost doesn’t shrink dramatically - automation increases volume and consistency of what’s being reviewed, but the responsibility itself stays with humans.
In a shape like this, ROI is recovered less from “review-process efficiency” and more from shortening the planning and production cycle.
Cross-Phase Checkpoints
| Question | One way to think about it |
|---|---|
| Where to start? | Phase 1 - research automation. A scope that’s feasible to prototype in a relatively short period. |
| Signal that Phase 2 is worth considering? | When marketers spend a non-trivial share of their time on copy drafting. |
| Signal that Phase 3 is worth considering? | Multi-day campaign lead times, need for event-driven response, meaningful accumulated learning data. |
| Where to begin under Korean financial security constraints? | In-region LLM or air-gapped LLM → in-house embedding → internal-tool RLS, in roughly that order. |
| Where to start with model selection? | Use a top-tier model in Phase 1; in Phase 2/3, downgrading the gathering layer to a cheaper model is an option. |
| Where do teams most often get stuck? | The HITL design in Phase 2 - starting with CLI-style input and re-architecting under operational pressure is a path that shows up frequently. |
| Where does ROI come from? | Different at each phase: research-time reduction, planning lead-time reduction, expanding the number of campaigns one marketer can run. |
Closing - Not the End of Automation, but Its Boundary
Even a Phase 3 system is closer to a tool for shortening the marketing cycle and maintaining consistency, not a place to delegate compliance responsibility. The two HITL gates aren’t obstacles to route around - they’re safety mechanisms the system relies on, drawing not “the end of automation” but the boundary of automation in governance terms.
In a Korean financial context, multi-agent adoption usually ends up reshaping authority and responsibility more than anything else. Phase 1 is a tool-selection problem, Phase 2 is a team-composition problem, Phase 3 is an operations-architecture problem - the underlying texture changes at each stage, and that’s the actual message of this roadmap.
There also isn’t a single right architecture in this space. Every tool, structure, and pattern that appears above is one example of one way to think about it; the same texture can be expressed through very different tool combinations. If this piece works as the first diagram drawn on a whiteboard at a PoC meeting, that’s enough - because the second and third diagrams will end up looking different in every organization anyway.
Related Posts

How to Organize Agents - Hierarchy, Graph, Swarm, Routing, and Skepticism
How do you organize the sliced agents. Four structures, paired with one skeptical paper that argues 'LLM swarms aren't really swarms.' The conclusion lands where it usually does - structure choice gets dragged along by pricing. Part 2 of the series.
Multi-Agent Workflow - 6 Patterns from Supervisor to Swarm
Six core patterns of multi-agent workflow (Supervisor / Sequential / Hierarchical / Network / Swarm / Map-Reduce), grounded in primary sources from LangGraph, CrewAI, OpenAI, and Anthropic. Each pattern's topology and fit, plus a decision framework for production.

How to Slice an Agent - Five Axes from 2026 Research
The five ways 2026 papers slice an agent, side by side. Two things stand out by the end: Role, Skill, and Judge are different names for the same concept, and the time-axis literature is nearly empty. Part 1 of the series.